시맨틱 청킹에 임베딩 모델을 바꿔보자
(24년 12월 추가)
글 내용과 관련해 강의를 런칭하였습니다. 더 많은 정보가 필요하신 분들은 참고해주세요!!
▪ 쿠폰코드: PRDTEA241202_auto
▪ 할인액: 4만원 (~25/1/5 까지 사용가능)
▪ 강의링크: https://bit.ly/3BayH1F
제가 직접 작성한 것이 아닌 AutoRAG를 같이 만든 김병욱 연구원이 쓴 글입니다.
지난 시맨틱 청킹에 문장 분리기를 바꿔보자 실험에서 우리는 시맨틱 청킹의 원리를 알아봤다.
전혀 기억이 나지 않아도 괜찮다! 빠르게 다시 알아보도록 하자.
0. 시맨틱 청킹 원리
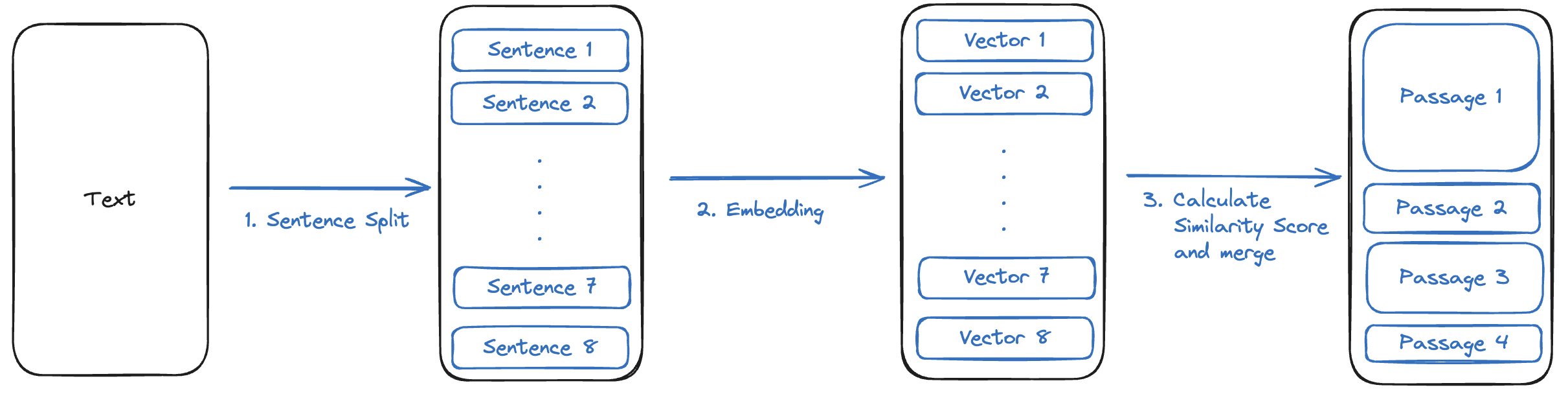
라마인덱스의 시맨틱 청킹은 크게 3가지 단계를 거친다
- 문장 분리기로 파싱된 텍스트를 문장으로 나눈다.
- 임베딩 모델로 문장을 벡터 임베딩 한다.
- 문장 간의 벡터 유사도 점수를 계산해서 기준보다 높으면 하나의 단락으로 합친다.
시맨틱 청킹에서는 문장 분리기와 임베딩 모델의 성능이 중요하겠는데? 🤔
그래서 다음 두 가지 실험을 해보기로 했었다.
- 문장 분리기를 바꿔가며, RAG 답변 성능 비교해보기
- 임베딩 모델을 바꿔가며, RAG 답변 성능 비교해보기
- 1번 문장 분리기 실험 결과 보러 가기 → 링크
이번 글에서는 두 번째 실험인 임베딩 모델만 바꿔가며 RAG 답변 성능을 비교해보고자 한다.
1. 임베딩 모델 선정
어떤 임베딩 모델로 실험을 해볼까?
우리의 실험에서 좋은 성능을 보여준 임베딩 모델을 살펴보자.
가장 먼저, 업스테이지 임베딩 모델 solar-embedding-1-large이 Top-k에 상관 없이 가장 좋은 성능을 보여주었다.
다음으로, 부분적으로 좋은 모습을 보여준 모델을 살펴보자
- Top-k 10 mAP, mRR에서 좋은 성능을 보여준
paraphrase-multilingual-mpnet-base-v2 - Top-k 50 mAP, mRR, NDCG에서 좋은 성능을 보여준
multilingual-e5-large-instruct
여기에 첫 실험에 사용했던 openai_ada_002까지 해서 4가지의 임베딩 모델로 RAG 답변 성능을 비교해보도록 하자.
📌 실험 임베딩 모델 목록
- OpenAI:
ada_002 - 업스테이지:
solar-embedding-1-large paraphrase-multilingual-mpnet-base-v2multilingual-e5-large-instruct
무엇보다 좋은 성능을 보여준 업스테이지 임베딩 모델의 결과가 기대된다 🤔

2. RAG 답변 성능 비교
지난 실험들과 역시 동일한 조건에서 진행하였다
2-1. G-Eval Consistency
- kiwi + OpenAI 임베딩: 3.3846
- kiwi + 업스테이지 임베딩: 3.359
- kiwi +
paraphrase-multilingual-mpnet-base-v2: 3.3846 - kiwi +
multilingual-e5-large-instruct: 3.4359
G-Eval Consistency가 같은 답변에도 0.15점씩은 점수가 튀었던 것을 감안했을 때, 별로 차이가 나지 않음을 알 수 있다
2-2. 정성평가
정성 평가 기준 역시 지난 실험들과 동일하다.
| OpenAI | Upstage | paraphrase | multilingual | |
|---|---|---|---|---|
| 1점 | 14 | 13 | 14 | 12 |
| 0.5점 | 2 | 2 | 2 | 2 |
| 0점 | 0 | 0 | 0 | 2 |
| -1점 | 0 | 1 | 0 | 0 |
| 평균 (16개) | 0.9375 | 0.8125 | 0.9375 | 0.8125 |
- 너무 길어서
paraphrase-multilingual-mpnet-base-v2는 paraphrase,multilingual-e5-large-instruct는 multilingual으로만 표현했다.
3. 결론
문장분리기와 마찬가지로 임베딩 모델의 성능이 일정 수준 이상이면, RAG 답변 성능에는 크게 영향을 주지 않는다.
📌주의점
- 문장 분리기는 특정 데이터마다 다른 성능을 보일 수 있다.
- G-Eval은 40개의 질문, 정성평가는 17개의 질문으로만 평가하여 통계적으로 유의미하지 않을 수 있다.
⭐ 마지막으로 AutoRAG 스타 한 번씩 부탁드립니다 ⭐